We will revisit the Service Desk best practices this weekend as we have several additions ready to go, but I wanted to cover how you, as an IT leader, can bring about much greater synergy within your IT organization. In many IT shops, and some that I found when I first arrived at a company, the IT is ‘siloed’ or separate into different divisions, with typically each division supporting a different business line. Inevitability there are frustrations with this approach, and they are particularly acute when a customer is served by two or more lines of business. How should you approach this situation as a leader and what are the best steps to take to improve IT’s delivery?
I think it is best first to understand what are the drivers for variations in IT organizations under large corporations. With that understanding we can then work out the best IT organizational and structural models to serve them. There are two primary sets of business drivers:
- those drivers that require IT to be closer to the business unit such as:
- improving market and business knowledge,
- achieving faster time-to-market (TTM),
- and the ability to be closer in step and under control of the business leads of each division
- those drivers that require IT to be more consolidated such as:
- achieving greater efficiencies,
- attaining a more holistic view of the customers,
- delivering greater consistency and quality
- providing greater scale and lower comprehensive risk
So, with these legitimate pushes, in two different directions, there is always a conflict in how IT should be organized. In some organizations, the history has been two or three years of being decentralized to enable IT to be more responsive to the business, and then, after costs are out of control, or risk is problematic, a new CFO, COO, or CEO comes in and IT is re-centralized. This pendulum swing back and forth, is not conducive to a high performance team, as IT senior staff either hunker down to avoid conflict, or play politics to be on the next ‘winning’ side. Further, given that business organizations have a typical life span of 3 to 4 years (or less) before being re-organized again, corollary changes in IT to match the prevailing business organization then cause havoc with IT systems and structures that have 10 or 20 year life spans. Moreover, implementing a full business applications suite and supporting business processes takes at least 3 years for decent-sized business division, so if organizations change in the interim, then much valuable investment is lost.
So it is best to design an IT organization and systems approach that meets both sets of drivers and anticipates that business organizational change will happen. The best solution for meeting both sets of drivers is to organize IT as a ‘hybrid‘ organization. In other words, some portions of IT should be organized to deliver scale, efficiency, and high quality, while others should be organized to deliver time to market, and market feature and innovation.
The functions that should be consolidated and organized centrally to deliver scale, efficiency and quality should include:
- Infrastructure areas, especially networks, data centers, servers and storage
- Information security
- Field support
- Service desk
- IT operations and IT production processes and tools
These functions should then be run as a ‘utility’ for the corporation. There should be allocation mechanisms in place to ensure proper usage and adequate investment in these key foundational elements. Every major service the utility delivers should be benchmarked at least every 18 months against industry to ensure delivery is at top quartile levels and best practices are adopted. And the utility teams should be relentlessly focused on continuous improvement with strong quality and risk practices in place.
The functions that should be aligned and organized along business lines to deliver time to market, market feature and innovation should include:
- Application development areas
- Internet and mobile applications
- Data marts, data reporting, and data analysis
These functions should be held accountable for high quality delivery. Effective release cycles should be in place to enable high utilization of the ‘build factory’ as well as a continuous cycle of feature delivery. These functions should be compared and marked against each other to ensure best practices are adopted and performance is improved.
And those functions which can be organized flexibly in either mode would be:
- Database
- Middleware
- Testing
- Applications Maintenance
- Data Warehousing
- Project Management
- Architecture
For these functions that can centralized or organized along business lines, it is possible to organize in a variety of ways. For example, systems integration testing could be centralized and unit test and system testing could be allocated by business line application team. Or, data base could have physical design and administration centralized and logical design and administration allocated by application team. There are some critical elements that should be singular or consolidated, including:
- if architecture is not centralized, there must be architecture council reporting to the CIO with final design authority
- there should be one set of project methodologies, tools, and process for all project managers
- there should be one data architecture team
- there should be one data warehouse physical design and infrastructure team
In essence, as the services are more commodity, or there is critical advantage to have a single solution (e.g. one view of the customer for the entire corporation) then you should establish a single team to be responsible for that service. And where you are looking for greater speed or better market knowledge, then organize IT into smaller teams closer to the business (but still with technical fiduciary accountabilities back to the CIO).
With this hybrid organization, as outlined in the diagram, you will be able to deliver the 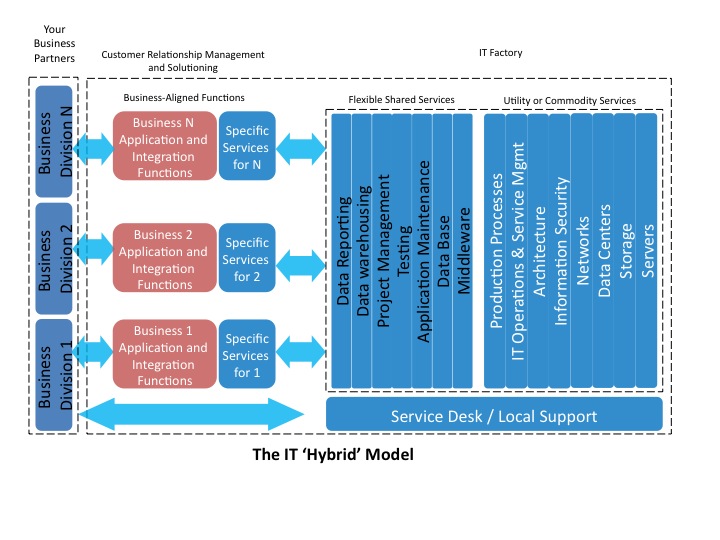 best of both worlds: outstanding utility services that provide cost and quality advantage and business-aligned services that provide TTM and market feature and innovation. .
best of both worlds: outstanding utility services that provide cost and quality advantage and business-aligned services that provide TTM and market feature and innovation. .
As CIO, you should look to optimize your organization using the ‘hybrid’ structure. If you are currently entirely siloed, then start the journey by making the business case for the most commodity of functions: networks, service desks, and data centers. It will be less costly, and there will be more capability and lower risk if these are integrated. As you successfully complete integration of these area, you can move up the chain to IT Operations, storage, and servers. As these areas are pooled and consolidated you should be able to release excess capacity and overheads while providing more scale and better capabilities. Another area to start could be to deliver a complete view of the customer across the corporation. This requires a single data architecture, good data stewardship by the business, and a consolidated data warehouse approach. Again, as functions are successfully consolidated, the next layer up can be addressed.
Similarly, if you are highly centralized, it will be difficult to maintain pace with multiple business units. It is often better to divest some level of integration to achieve a faster TTM or better business unit support. Pilot an application or integration team in those business areas where innovation and TTM are most important or business complexity is highest. Maintain good oversight but also provide the freedom for the groups to perform in their new accountabilities.
And realize that you can dial up or down the level of integration within the hybrid model. Obviously you would not want to decentralize commodity functions like the network or centralize all application work, but there is the opportunity to vary intermediate functions to meet the business needs. And by staying within the hybrid framework, you can deliver to the business needs without careening from a fully centralized to a decentralized model every three to five years and all the damage that such change causes to the IT team and systems.
There are additional variations that can be made to the model to accommodate organizational size and scope (e.g., global versus regional and local) that I have not covered here. What variations to the hybrid or other models have you used with success? Please do share.
Best, Jim



