With the ongoing stampede to public cloud platforms, it is worth a clearer look at some of the factors leading to such rapid growth. Amazon, Azure, Google, and IBM and a host of other public cloud services saw continued strong growth in 2018 of 21% to $175B, extending a long run of rapid revenue growth for the industry, according to Gartner in a recent Forbes article. Public cloud services, under Gartner’s definition, include a broad range of services from more traditional SaaS to infrastructure services (IaaS and PaaS) as well as business process services. IaaS, perhaps most closely associated with AWS, is forecast to grow 26% in 2019, with total revenues increasing from $31B in 2018 to $39.5B in 2019. AWS does have the lion’s share of this market with 80% of enterprises either experimenting with or using AWS as their preferred platform. Microsoft’s Azure continues to make inroads as well with increase of enterprises using the Azure platform from 43% to 58%. And Google is proclaiming a recent upsurge in its cloud services in its quarterly earning announcement. It is worth noting though that both more traditional SaaS and private cloud implementations are expect to also grow at near 30% rates for the next decade – essentially matching or even exceeding public cloud infrastructure growth rates over the same time period. The industry with the highest adoption rates of both private and public cloud is the financial services industry where adoption (usage) rates above 50% are common and even rates close to 100% are occurring versus median rates for all industries of 19%.
At Danske Bank, we are close to completing a 4 year infrastructure transformation program that has migrated our entire application portfolio from proprietary dedicated server farms in 5 obsolete data centers to a modern private cloud environment in 2 data centers. Of course, we migrated and updated our mainframe complex as well. Over that time, we have also acquired business software that is SaaS-provided as well as experimented with or leveraged smaller public cloud environments. With this migration led by our CTO Jan Steen Olsen, we have eliminated nearly all of our infrastructure layer technical debt, reduced production incidents dramatically (by more than a 95% ), and correspondingly improved resiliency, security, access management, and performance. Below is a chart that shows the improved customer impact availability achieved through the migration, insourcing, and adoption of best practice.
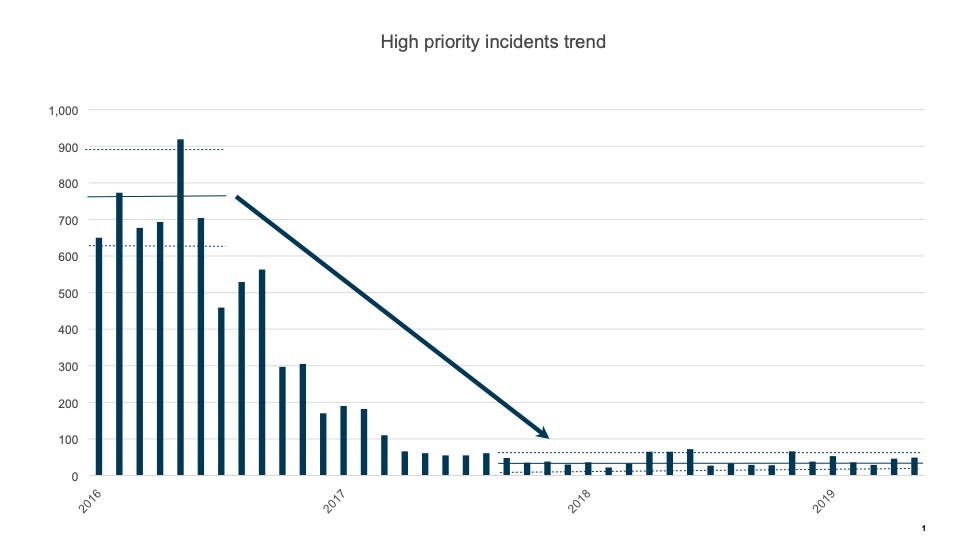
These are truly remarkable results that enable Danske Bank to deliver superior service to our customers. Such reliability for online and mobile systems is critical in the digital age. Our IT infrastructure and applications teams worked closely together to accomplish the migration to our new, ‘pristine’ infrastructure. The data center design and migration was driven by our senior engineers with strong input from top industry experts, particularly CS Technology. A critical principle we followed was not to just move old servers to the new centers but instead to set up a modern and secure ‘enclave’ private cloud and migrate old to new. Of course this is a great deal more work and requires extensive update and testing to the applications. Working closely together, our architects and infrastructure engineers partnered to design our private that established templates and services up to our middleware, API, and database layers. There were plenty of bumps in the road especially in the our earliest migrations as worked out the cloud designs, but our CIO Fredrik Lindstrom and application teams dug in, and in partnering with the infrastructure team, made room for the updates and testing, and successfully converted our legacy distributed systems to the new private cloud environments. While certainly a lengthy and complex process, we were ultimately successful. We are now reaping the benefits of a fully modernized cloud environment with rapid server implementation times and lower long term costs (you can see further guidelines here on how to build a private cloud). In fact, we have benchmarked our private cloud environment and it is 20 to 70% less expensive than comparable commercial offerings (including AWS and Azure). A remarkable achievement indeed and for the feather in the cap, the program led by Magnus Jacobsen was executed on a relatively flat budget as we used savings generated from insourcing and consolidations to fund much of the needed investments.
Throughout the design and the migration, we have stayed abreast of the cloud investments and results at many peer institutions and elsewhere. We have always looked at our cloud transformation as an infrastructure quality solution that could provide secondary performance and cycle time and cost savings. But our core objective was focused on achieving the availability and resiliency benefits and eliminating the massive risk due to legacy data center environmentals. Yet, much of the dialogue in the industry is focused on cloud as a time to market and cost solution for companies with complex legacy environments, enabling them to somehow significantly reduce systems costs and greatly improve development time to market.
Let’s consider how realistic is this rationale. First, how real is the promise of reduced development time to market due to public cloud? Perhaps, if you are comparing an AWS implementation to a traditional proprietary server shop with mediocre service and lengthy deliver times for even rudimentary servers, then, yes, you enable development teams to dial up their server capacity much more easily and quickly. But compared to a modern, private cloud implementation, the time to implement a new server for an application is (or should be) comparable. So, on an apples to apples basis, generally public and private cloud are comparably quick. More importantly though, for a business application or service that is being developed, the server implementation tasks should be done as parallel tasks to the primary development work with little to no impact on the overall development schedule or time to market. In fact, the largest tasks that take up time in application development are often the project initiation, approval, and definition phases (for traditional waterfall) and project initiation, approval, and initial sprint phases for Agile projects. In other words, management decisions and defining what the business wants the solution to do remain the biggest and longest tasks. If you are looking to improve your time to market, these are the areas where IT leadership should focus. Improving your time to get from ‘idea to project’ is typically a good investment in large organizations. Medium and large corporations are often constrained as much by the annual finance process and investment approval steps as any other factor. We are all familiar with investment processes that require several different organizations to agree and many hurdles to be cleared before the idea can be approved. And the larger the organization, the more likely the investment process is the largest impact to time to market.
Even after you have approval for the idea and the project is funded, the next lengthy step is often ensuring that adequate business, design, and technology resources are allocated and there is enough priority to get the project off the ground. Most large IT organizations are overwhelmed with too many projects, too much work and not enough time or resources. Proper prioritization and ensuring that not too many projects are in flights at any one time are crucial to enable projects to work at reasonable speed. Once the funding and resources are in place, then adopting proper agile approaches (e.g. joint technology and business development agile methods) can greatly improve the time to market.
Thus, must time to market issues have little to do with infrastructure and cloud options and almost everything to do with management and leadership challenges. And the larger the organization, the harder it is to focus and streamline. Perhaps the most important part of your investment process is on what not to do, so that you can focus your efforts on the most important development projects. To attain the prized time to market so important in today’s digital competition, drive instead for a smooth investment process coupled with a properly allocated and flexible development teams and agile processes. Streamlining these processes, and ensuring effective project startups (project manager assigned, dedicated resources, etc) will yield material time to market improvements. And having a modern cloud environment will then nicely support your streamlined initiatives.
On the cost promise of public cloud, I find it surprising that many organizations are looking to public cloud as silver bullet for improving their costs. For either legacy or modern applications, the largest costs are the software development and software maintenance cost – ranging anywhere from 50% to 70% percent of the full lifetime cost of a system. Next will come IT operations – running the systems and the production environment – as well as IT security and networks at around 15-20% of total cost. This leaves 15 to 30% of lifetime cost for infrastructure, including databases, middleware, and messaging as well as the servers and data centers. Thus, the servers and storage total perhaps 10-15% of the lifetime cost. Perhaps you can achieve a a 10%, or even 20% or 30% reduction in this cost area, for a total systems cost reduction of 2-5%. And if you have a modern environment, public cloud would actually be at a cost disadvantage (at Danske Bank, our new private cloud costs are 20% to 70% lower than AWS, Azure, and other public clouds). Further, focusing on a 2% or 5% server cost reduction will not transform your overall cost picture in IT. Major efficiency gains in IT will come from far better performance in your software development and maintenance — improving productivity, having a better and more skilled workforce with fewer contractors, or leveraging APIs and other techniques to reduce technical and improve software flexibility. It is disingenuous to suggest you are tackling primary systems costs and making a difference for your firm with public cloud. . You can deliver 10x total systems cost improvements by introducing and rolling out software development best practices, achieving an improved workforce mix and simplifying your systems landscape than simply substituting public cloud for your current environment. And as I noted earlier, we have actually achieved lower costs with a private cloud solution versus commercial public cloud offerings. And there are hidden factors to consider with public cloud. For example, when testing a new app on your private cloud, you can run the scripts in off hours to your heart’s content at minimal to no cost, but you would need to watch your usage carefully if on a public cloud, as all usage results in costs. The more variable your workload is also means it could cost less on a public cloud — the reverse being the more stable the total workload is, the more likely you can achieve significant savings with private cloud.
On a final note, with public cloud solutions come lock-in, not unlike previous generations of proprietary hardware or wholesale outsourcing. I am certain a few of you recall the extensions done to proprietary Unix flavors like AIX and HP-UX that provided modest gains but then increased lock-in of an application to that vendor’s platform. Of course, the cost increases from these vendors came later as did migration hurdles to new and better solutions. The same feature extension game occurs today in the public cloud setting with Azure or AWS or others. Once you write your applications to take advantage of their proprietary features, you have now become an annuity stream for that vendor, and any future migration off of their cloud with be arduous and expensive. Your ability to move to another vendor will typically be eroded and compromised with each system upgrade you implement. Future license and support price increases will need to be accepted unless you are willing to take on a costly migration. And you have now committed your firm’s IT systems and data to be handled elsewhere with less control — potentially a long term problem in the digital age. Note your application and upgrade schedules are now determined by the cloud vendor, not by you. If you have legacy applications (as we all do) that rely on an older version of infrastructure software or middleware, thus must be upgraded and keep pace, otherwise they don’t work. And don’t count on a rollback if problems are found after the upgrades by the cloud vendor.
Perhaps more concerning, in this age of ever bigger hacks, is that the public cloud environments become the biggest targets for hackers, from criminal gangs to state sponsored. And while, they have much larger security resources, there is still a rich target surface for hackers. The recent Capital One breach is a reminder that proper security remains a major task for the cloud customer.
In my judgement, certainly larger corporations are better off maintaining control of their digital capabilities with a private cloud environment than a public cloud. This will likely be supplemented with a multi-cloud environment to enable key SaaS capabilities or leverage public cloud scalability and variable expense for non-core applications. And with the improving economies of server technology and improved cloud automation tools, these environments can also be effectively implemented by medium-sized corporations as well. Having the best digital capabilities — and controlling them for your firm — is key to outcompeting in most industries today. If you have the scale to retain control of your digital environment and data assets, then this is the best course to enabling future digital success.
What is your public or private cloud experience? Has your organization mastered private, public, or multi-cloud? Please share your thoughts and comments.
Best, Jim
P.S. Worth noting that public clouds are not immune to availability issues as well as reported here.