Robotics, AI, Advanced Analytics, BPM, Agile, DevOps, Cloud… Technology and business leaders are inundated with marketing pitches and consulting proposals on the latest technology, and how, by applying them, they can win against the competition. Unfortunately far too often, the implementations of advanced technology in their organizations fall well short of the promises: they’re expensive, require enormous organizational change that doesn’t happen, or they just doesn’t produce nearly the expected results. Often, applying advanced technology achieves modest success only in a few areas, for a slim portion of the enterprise while broader impact and benefits never seem to materialize. Frequently, the highly hyped efforts have overhyped success as a pilot only to peter out well before the promised returns are delivered. Organizations and teams then quietly go about their business as they have always done, now with added complexity and perhaps a bit more cynical and disengaged.
The far too frequent inability to broadly digitalize and leverage advanced technologies means most organizations remain anchored to legacy systems and processes with only digital window dressing on interfaces and minimal true commercial digitalization success. Some of the lack of success is due to the shortcomings of the technologies and tools themselves – some advanced technologies are truly overhyped and not ready for primetime, but more often, the issue is due to the adoption approach within the organization and the leadership and discipline necessary to fully implement new technologies at scale.
Advanced technology implementations are not silver bullets that can be readily adopted with benefits delivered in a snap. As with any significant transformation in a large organization, advanced technology initiatives require senior sponsorship and change management. Further, because of the specialty skills, new tools and methods, new personnel, and critically, new ways of getting the work done, there is additional complexity and more possibilities for issues and failures with advanced technology implementations. Thus, the transformation program must plan and anticipate to ensure these factors are properly addressed to enable the implementation to succeed. Having helped implement successfully a number of advanced technologies at large firms, I have outlined the key steps to successful advanced technology adoption as well as major pitfalls to be avoided.
Foremost, leadership and sponsorship must be full in place before embarking on a broad implementation of an advanced technology. In addition, it is particularly crucial at integration points, where advanced technologies require different processes and cycle times than those of the legacy organization. For example, traditional, waterfall financial planning processes and normal but typically undisciplined business decision processes can cause great friction when they are used to drive agile technology projects. The result of an unmanaged integration like this is then failing or greatly underperforming agile projects accompanied by frustration on the technology side and misunderstanding and missed expectations on the business side.
Success is also far more likely to come if the ventures into advanced technologies are sober and iterative. An iterative process, building success but starting small and growing its scope, while at each step, using a strong feedback loop to improve the approach and address weaknesses. Further, robust change management should accompany the effort given the level of transformation. Such change management should encompass all of the ‘human’ and organizational aspects from communications to adjusting incentives and goals, to defining new roles properly, to training and coaching, and ensuring the structures and responsibilities support the new ways of working.
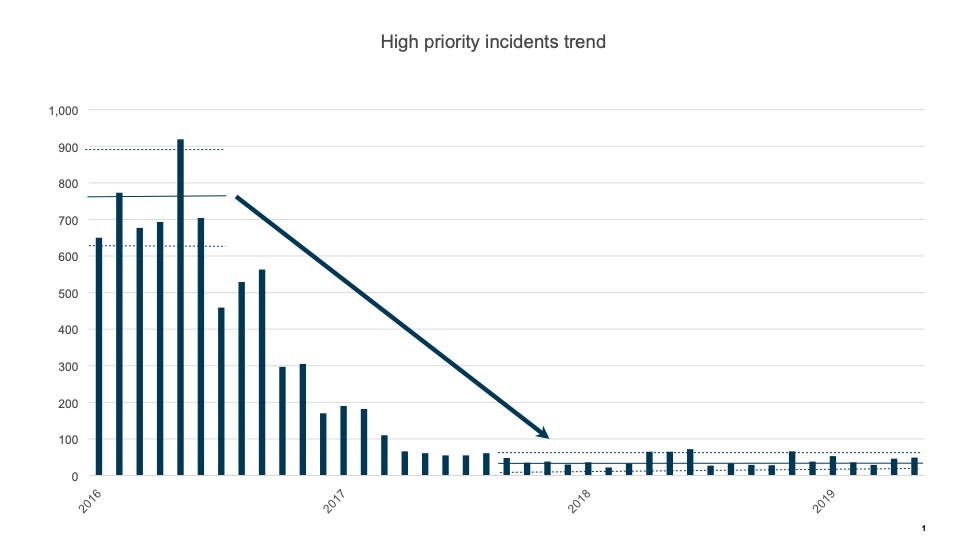
Let’s start with Robotics and Business Process Management, two automation and workflow alternatives to traditional IT and software programming. Robotics or better put, Robotic Process Automation (RPA) has been a rapidly growing technology in the past 5 years, and the forecasts are for even more rapid growth over the next 5 years. For those not familiar, here is a reference page for a quick primer on RPA. Briefly, RPA is the use of software robots to do repetitive tasks that a human typically does when interfacing with a software application. RPA tools allow organizations to quickly set up robots to handle basic tasks thus freeing up staff time from repetitive typing tasks. At Danske Bank, since our initial implementation in 2014 (yes, 2014), we have implemented well over 300 robots leveraging the Blue Prism toolset. Each robot that was built was typically completed in a 2 to 6 week cycle where the automation suggestion was initially analyzed, reviewed for applicability and business return, and then prioritized. We had set up multiple ‘robotic teams’ to handle the development and implementation. Once a robotic team freed up, they would then go to work on the next best idea. The team would take the roughly drafted idea, further analyze and then build and deliver it into production (in two to six weeks). Each robot implemented could save anywhere from a third of an FTE to 30 FTEs (or even more). Additionally, and usually of greater value, the automation typically increased process quality (no typos) and improved cycle time.
Because the cycle time and actual robotic analyze, build, and implement process were greatly different than those of traditional IT projects, it was necessary to build a different discovery, review, and approval process than those for traditional IT projects. Traditional IT (unfortunately) often operates on an annual planning cycle with lengthy input and decision cycles with plenty of debate and tradeoffs considered by management. The effort to decision a traditional mid-sized or large IT project would dwarf the total effort required for implementation of a robot (!) which then would be impractical and wasteful. Thus, a very different review and approval process is required to match the advanced technology implementation. Here, a far more streamlined and ‘pipelined’ approach was used for robotic automation projects. Instead of funding each project separately, a ‘bucket’ of funding was set up annually for Robotics that then had certain hurdle criteria for each robotic project to be prioritized. A backlog of automation ideas was generated by business and operations teams and then based on an quick analysis of ease of implementation, FTE savings, and core functional capability, the ideas were prioritized. Typical hurdle rates were a 6 month or less ROI (yes, the implementation would save more money within 6 months than the full cost of implementation) and at least .5 FTE of savings. Further, implementations that required completing critical utility functionality (e.g., interfacing with the email system or financial approval system) were prioritized early in our Robotics implementation to enable reuse of these capabilities by later automation efforts.
The end result was a strong pipeline of worthwhile ideas that could be easily prioritized and approved. This steady stream of ideas was then fed into multiple independent robotics development teams that were each composed of business or operations analysts, process analysts, and technology developers (skilled in the RPA tool) that could take the next best idea out of the pipeline and work it as soon as that team were ready. This pipeline and independent development factory line approach greatly improved time to market and productivity. So, not only can you leverage the new capabilities and speed of the advanced technology, you also eliminate the stop-go and wait time inefficiencies of traditional projects and approval processes.
To effectively scale advanced technology in a large firm requires proper structure and sponsorship. Alternative scaling approaches can range from a broad or decentralized approach where each business unit or IT team experiment and try to implement the technology to a fully centralized and controlled structure where one program team is tasked to implement and roll it out across the enterprise. While constraints (scarce resources, desire for control (local or central), lack of senior sponsorship) often play a role in dictating the structure, technology leaders should recognize that taking a Center of Excellence (COE) approach is far more likely to succeed at scale for advanced technology implementations. I strongly recommend the COE approach as it addresses fundamental weaknesses that will hamper both the completely centralized or the decentralized approaches and is much more likely to succeed.
When rolling out an advanced technology, the first challenge to overcome is the difficulty to attract and retain advanced technology talent. It is worthwhile to note that just because your firm has decided to embark on adopting an advanced technology does not mean you will be able to easily attract the critical talent to design and implement the technology. Nearly every organization is looking for these talents, and thus you need to have a compelling proposition to attract the top engineers and leaders. In fact, few strong talents would want to join a decentralized structure where it’s not clear who is deciding on toolset and architecture, and the projects have only local sponsors without clear enterprise charters, mandates or impact. Similarly, they will be turned off from top-heavy, centralized programs that will likely plod along for years and not necessarily complete the most important work. By leveraging a COE, where the most knowledgeable talent is concentrated and where demand for services is driven by the prioritizing the areas with the highest needs, your firm will be able attract talent as well as establish an effective utility and deliver the most commercial value. And the best experts and experienced engineers will want to work in a structure where they can both drive the most value as well as set the example for how to get things done. Even better, with a COE construct, each project leverages the knowledge of the prior projects, thus improving productivity and reuse with each implementation. As you scale and increase volume, you get better at doing the work. With a decentralized approach, you often end up with discord where multiple toolsets, multiple groups of experts, and inexperienced users often lead to teams in conflict with each other or duplicating work.
When the COE is initially set up, the senior analysts, process engineers and development engineers in the COE should ensure proper RPA toolset selection and architecture. Further, they lead the definition of the analysis and prioritization methodology. Once projects begin to be implemented, they maintain the libraries of modules and encourage reuse, and they ensure the toolsets and systems are properly updated and supported for production including backups, updates and adequate capacity. Thus, as the use of RPAs grow, your productivity improves with scale, ensuring more and broader commercial successes. By assigning responsibility for the service to your best advanced technology staff, they will plan and avoid pitfalls due to immature, disparate implementations that often fail 12 or 18 months after initial pilots.
Importantly though, in a COE model, demand is not determined by the central team, but rather, is developed by the COE team consulting with each business unit to determine the appetite and capability to tackle automation projects. This consulting results in a rough portfolio being drafted, which is then used as the basis to fund that level of advanced technology implementation for that business unit. Once the draft portfolio is developed and approved, it is jointly and tightly managed by the business unit with the COE to ensure greatest return. With such an arrangement, the business unit feels in control, the planned work is in the areas that the business feels is most appropriate, and the business unit can then line up the necessary resources, direction, and adoption to ensure the automation succeeds commercially (since it is their ambition). Allowing the business unit to drive the demand avoids the typical flaws of a completely centralized model where an organization separate from the unit where the implementation will occur makes the decisions on where and what to implement. Such centralized structures usually result in discord and dissatisfaction between the units doing ‘real business work’ and an ‘ivory tower’ central team that doesn’t listen well. By using a COE with a demand driven portfolio, you get the advantages of a single high performance team yet avoid the pitfalls of ‘central planning’ which often turns into ‘central diktat’.
As it turns out, the COE approach is also valuable for BPM rollouts. In fact, it could be synergistic to run both RPA and BPM from ‘sister’ COEs. Yes, BPM will require more setup and has a longer 6 to 12 or even 18 week development cycle. Experts in BPM are not necessarily experts in RPA tools but they will share process engineering skills and documentation. Further, problems or automation that is too complex for RPAs could be perfectly suited for BPM, thus enabling a broader level of automation of your processes. In fact, some automation or digitalization solutions may turn out to be best using a mix of RPA and BPM. Treating them as similar, each with their own COE structure, their own methodology and their own business demand stream but where they leverage common process knowledge and work together on more complex solutions will yield optimal results and progress.
A COE approach can also work well for advanced analytics. In my experience, it is very difficult for the business unit to attract and retain critical data analytics talent. But, by establishing a COE you can more easily attract enough senior and mid talent for the entire enterprise. Next, you can establish a junior pipeline as part of the COE that works alongside the senior talent and is trained and coached to advance as you experience inevitable attrition for these skills. Further, I recommend establishing Analytics COEs for each ‘data cluster’ so that models and approaches can be shared within a COE that is driven by the appropriate business units. In Financial Services, we found success with a ‘Customer and Product’ Analytics team, a ‘Fraud and Security’ team and a ‘Financing and Risk’ team. Of course, organize the COEs along the data clusters that make sense for your business. This allows greater focus by a COE and impressive development and improvement of their data models, business knowledge and thus results. Again, the COE must be supplemented by full senior sponsorship and a comprehensive change management program.
The race is on to digitalize and take advantage of the latest advanced technologies. Leveraging these practices and approaches will enable your shop to more forward more quickly with advanced technology. What alternatives have you seen or implemented that were successful?
I look forward to hearing your comments and wish you the best on attaining outstanding advanced technology capabilities for your organization. Best, Jim