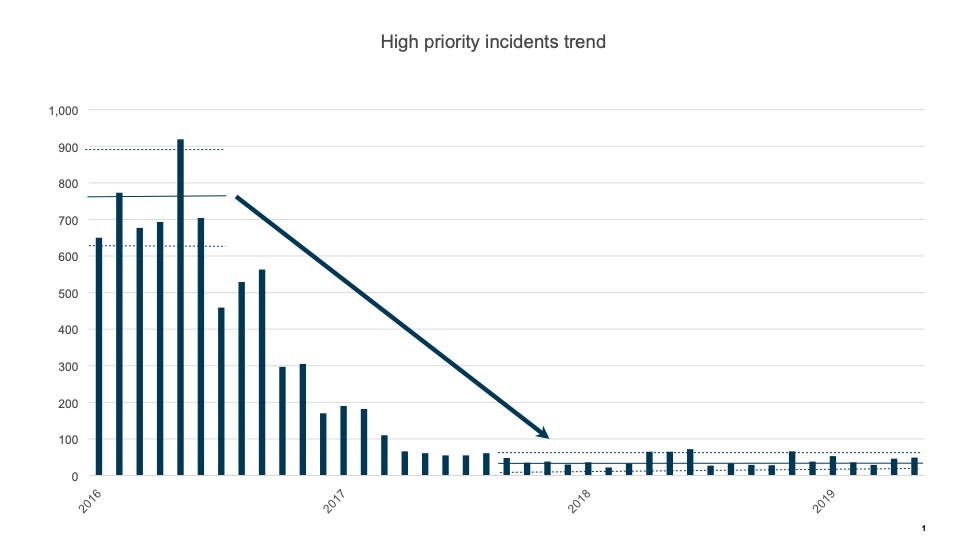
Happy New Year! As we embark on 2020, we unfortunately must recall that 2019 was a relatively dismal year in terms of industry performance against hackers. Even as the world becomes more digital, data breaches and IT failures appear to be multiplying. In fact, 2019 has been called the ‘Year of the Massive Data Breaches’. And worse, many of the breaches were suffered by large and sophisticated corporations: Capital One, Facebook, and Twitter among others. In our challenging digital world, business executives and IT leaders need to take stock in 2020 of too frequent past incompetence and inadequate protection and apply lessons learned to protect their companies, their reputations, and most importantly, their customers. With GDPR in Europe and the new California Privacy regulations, it is also becoming a matter of meeting societal responsibilities and avoiding fines, as well as doing right by the customer.
I recently met with a former technology colleague Peter Makohon, who is a foremost expert in IT Security, and he outlined 7 questions you should ask (and try to answer) to understand how well your corporation is protected. Here are the 7 questions:
- What’s on your network?
Knowing what’s on your corporate network is the most fundamental question to be answered to properly manage your information technology and keep your enterprise secure. Because of the structure that most corporate networks are built on, if a device or program resides on your network, it can usually easily traverse and infiltrate across your network to critical data or assets. Knowing what is on your network, and that it should be on your network, is necessary to secure your critical data and assets. Your information security team should be working closely with the network engineers to install the right monitors and automated agents so you can gather identifying information from the traffic as it passes through your network. As devices and programs speak with other programs or devices, “network communication trails” are left like digital footprints that can ensure you know what is on your network. - What applications are running on your computers? The second most important question to ask is do we know what programs are installed and running on each of the computers within the enterprise. The list of programs and applications should be compared to a list of expected known good applications along with a list of known bad or unwanted applications. Anything that is not on the known good or the known bad list should be put into a malware forensics sandbox for further analysis. Once a list of applications is put together anything new that shows up each day should be also reviewed in order to determine whether it really belongs in the environment. Your engineers should be doing more that simple comparisons, they should be leveraging hashing to ensure the identity of the application is verified. Of course, ensuring your environment is properly controlled and administered to minimize the possible downloads of malware or fraudulent software is a key protection to put in place.
- Who are your computers talking to? Once the network devices and applications are known, analysis can then focus on understanding what destinations are the computers sending and receiving traffic from/to. It is paramount to understand whether or not the traffic is staying within the enterprise or whether it is traversing across the Internet or to external destinations. An organization’s supply chain should be analyzed to determine which of these outbound and inbound connections are going to valid, approved supplier systems and connections. Every external destination should be compared to known malware or fraudulent sites. And for all external transmissions, are they properly encrypted and protected?
- Where is your data stored and where has it been replicated to? Perhaps the most difficult question to answer for most companies involves understanding where your company’s and customers’ confidential and restricted data is being stored and sent to, both within your enterprise and the extended ecosystem of suppliers. Production data can sometimes find its way onto user machines to be used for ad hoc analysis. This dispersal of data makes protection (and subsequent required regulatory deletion) of customer confidential data much more difficult. Look for your IT team to minimize and eliminate such ‘non-production’ proliferation.
- What does the environment look like to an attacker? Every enterprise has a cyber profile that is visible from outside of the organization. This includes technology and its characteristics on the Internet; information about jobs being offered by an organization; information about employees, including social media; and even vendors who reveal that they have sold technology and products to your company. It is important to understand what an attacker can see and take steps to reduce the amount of information that is being provided to fill in the “digital puzzle” that the attacker is trying to assemble in order to increase the likelihood of their success. Your websites should ensure their code is obfuscated and not visible to visitors of the site. Most importantly, all interfaces should be properly patched and fully up-to-date to prevent attackers from simply using known attacks to penetrate your systems.
- Are your security controls providing adequate coverage? Are they effective? Just because your organization has spent a considerable amount of time and money purchasing and deploying security measures does not mean that the controls are deployed effectively and are providing the necessary coverage. 2019 has demonstrated too many organizations – with sophisticated and well-funded IT teams – missed the boat on security basics. Too many breaches were successful through elementary attacks, leveraging known security problems in common software. Your IT and security teams need to monitor the environment on a 7×24 basis (leveraging a Security Operations Center or SOC) to identify usual behavior and uncover attacks. Second, your teams should test your controls regularly. Automated control testing solutions should be utilized in order to understand whether or not the controls are appropriately deployed and configured. Further, external vendors should be engaged to attempt to breach your environment – so called ‘Red teams’ can expose vulnerabilities that you have overlooked and enable you to correct the gaps before real hackers find them.
- Are your employees educated and aware of the many threats and typical attack techniques of fraudsters? Often, helpful and unaware staff are the weakest link in a security defense framework, enabling cybercriminals entry through clicking on malware, helping unverified outsiders navigate your company, and inadequately verifying and checking requested actions. Companies have been defrauded by by simple email ‘spoofing’ where a fraudster poses as the CEO by making his email appear to come from the CEO. The accounting department then doesn’t ask any questions of an unusual request (e.g. to wire money to China for a ‘secret’ acquisition) and the company is then defrauded of millions because of employee unawareness. It is important to keep employees educated on the fraud techniques and hacker attacks, and if not sure what to do, to be cautious and call the information security department.
How comfortable are you answering these questions? Anything you would change or add? While difficult, proper investment and implementation of information security is critical to secure your company’s and customer’s assets in 2020. Let’s make this year better than 2019!
Best, Jim Ditmore