As we covered in our first post on this topic, since the mid-90s, companies have used offshoring to achieve cost and capacity advantages in IT. Offshoring was a favored option to address Y2K issues and has continued to expand at a steady rate throughout the past twenty years. But many companies still approach offshoring as ‘out-tasking’ and fail to leverage the many advantages of a truly global and high performance work force.
With out-tasking, companies take a limited set of functions or ‘tasks’ and move these to the offshore team. They often achieve initial economic advantage through labor arbitrage and perhaps some improvement in quality as the tasks are documented and standardized in order to make it easier to transition the work to the new location. This constitutes the first level of a global team: offshore service provider. But larger benefits around are often lost and only select organizations have matured the model to its highest performance level as ‘global service centers’.
So, how do you achieve high performance global service centers instead of suboptimal offshore service providers? As discussed previously, you must establish the right ‘global footprint’ for your organization. Here we will cover the second half of getting to global service centers: implementing a ‘global team’ model. Combined with the right footprint, you will be able to achieve global service centers and enable competitive advantage.
Global team elements include:
- consistent global goals and vision across global sites with commensurate rewards and recognition by site
- a matrix team structure that enables both integrated processes and local and global leadership and controls
- clarity on roles based on functional responsibility and strategic competence rather than geographic location
- the opportunity for growth globally from a junior position to a senior leader
- close partnership with local universities and key suppliers at each strategic location
To understand the variation in performance for the different structures, first consider the effectiveness of your entire team – across the globe – on several dimensions:
- level of competence (skill, experience)
- productivity, ability to improve current work
- ownership and engagement
- customization and innovation contributions
- source of future leaders
For an offshore service provider, where work has been out-tasked to a particular site, the team can provide similar or in some cases, better levels of competence. Because of the lower cost in the offshore location, if there is adequate skilled labour, the offshore service provider can more easily acquire such skill and experience within a given budget. A recognizable global brand helps with this talent acquisition. But since only tasks are sent to the center, productivity and continuous improvement can only be applied to the portions of the process within the center. Requirements, design, and other early stage activities are often left primarily to the ‘home office’ with little ability for the offshore center to influence. Further, the process standards and ownership typically remain at home office as well, even though most implementation may be done at the offshore service provider. This creates a further gap where implications of new standards or home office process ‘improvements’ must be borne by the offshore service provider even if the theory does not work well in actual practice. And since implementation and customer interfaces are often limited as well, the offshore service provider receives little real feedback, furthering constraining the improvement cycle.
For the offshore service provider, the ability to improve processes and productivity is limited to local optimization only, and capabilities are often at the whims of poor decisions from a distant home office. More comprehensive productivity and process improvements can be achieved by devolving competency authority to the primary team executing the work. So, if most testing is done in India, then the testing process ownership and testing best practices responsibility should reside in India. By shifting process ownership closer to the primary team, there will be a natural interchange and flow of ideas and feedback that will result in better improvements, better ownership of the process, and better results. The process can and should still be consistent globally, the primary competency ownership just resides at its primary practice location. This will result in a highly competent team striving to be among the best in the world. Even better, the best test administrators can now aspire to become test best practice experts and see a longer career path at the offshore location. Their productivity and knowledge levels will improve significantly. These improvements will reduce attrition and increase employee engagement in the test team, not just in India but globally. In essence, by moving from proper task placement to proper competency placement, you enable both the offshore site and the home sites to perform better on both team skill and experience, as well as team productivity and process improvement.
Proper competency placement begins the movement of your sites from offshore service providers to global service excellence. Couple competency placement with transparent reporting on the key metrics for the selected competencies (e.g., all test teams, across the globe, should report based on best in class operational metrics) and drive improvement cycles (local and global) based on findings from the metrics. Full execution of these three adjustments will enable you to achieve sustained productivity improvements of 10 to 30% and lower attrition rates (of your best staff) by 20 to 40%.
It is important to understand that pairing competency leadership with primary execution is required in IT disciplines much more so than other fields due to the rapid fluidity and advance of technology practices, the frequent need to engage multiple levels of the same expertise to resource and complete projects, and the ambiguity and lack of clear industry standards in many IT engineering areas. In many other industries (manufacturing, chemicals, petroleum), stratification between engineering design and implementation is far more rigorous and possible given the standardization of roles and slower pace of change. Thus, organizations can operate far closer to optimum even with task offshoring that is just not possible in the IT space over any sustained time frame.
To move beyond global competency excellence, the structures around functions (the entire processes, teams and leadership that deliver a service) must be optimized and aligned. First and foremost, goals and agenda must be set consistently across the globe for all sites. There can be no sub agendas where offshore sites focus only on meeting there SLAs or capturing a profit, instead the goals must be the appropriate IT goals globally. (Obviously, for tax implications, certain revenue and profit overheads will be achieved but that is an administrative process not an IT goal. )
Functional optimization is achieved by integrating the functional management across the globe where it becomes the primary management structure. Site and resource leadership is secondary to the functional management structure. It is important to maintain such site leadership to meet regulatory and corporate requirements as well as provide local guidance, but the goals, plans, initiatives, and even day-to-day activities flow through a natural functional leadership structure. There is of course a matrix management approach where often the direct line for reporting and legal purposes is the site management, but the core work is directed via the functional leadership. Most large international companies have mastered this matrix management approach and staff and management understand how to properly work within such a setup.
It is worth noting that within any large services corporation ‘functional’ management will reign supreme over ‘site’ management. For example, in a debate deciding what are the critical projects to be tackled by the IT development team, it is the functional leaders working closely with the global business units that will define the priorities and make the decisions. And if the organization has a site-led offshore development shop, they will find out about the resources required long after the decisions are made (and be required to simply fulfill the task). Site management is simply viewed as not having worthy knowledge or authority to participate in any major debate. Thus if you have you offshore centers singularly aligned to site leadership all the way up the corporate chain, the ability to influence or participate in corporate decisions is minimal. However, if you have matrixed the structure to include a primary functional reporting mechanism, then the offshore team will have some level of representation. This increases particularly as manager and senior managers populate the offshore site and are enable functional control back into home offices or other sites. Thus the testing team, as discussed earlier, if it is primarily located in India, would have not just responsibility for the competency and process direction and goals but also would have the global test senior leader at its site who would have test teams back at the home office and other sites. This structure enables functional guidance and leadership from a position of strength. Now, priorities, goals, initiatives, functional direction can flow smoothly from around the globe to best inform the functional direction. Staff in offshore locations now feel committed to the function resulting in far more energy and innovation arising from these sites. The corporation now benefits from having a much broader pool of strong candidates for leadership positions. And not just more diverse candidates, but candidates who understand a global operating model and comfortable reaching across time zones and cultures. Just what is needed to compete globally in the business. The chart below represents this transition from task to competency to function optimization.
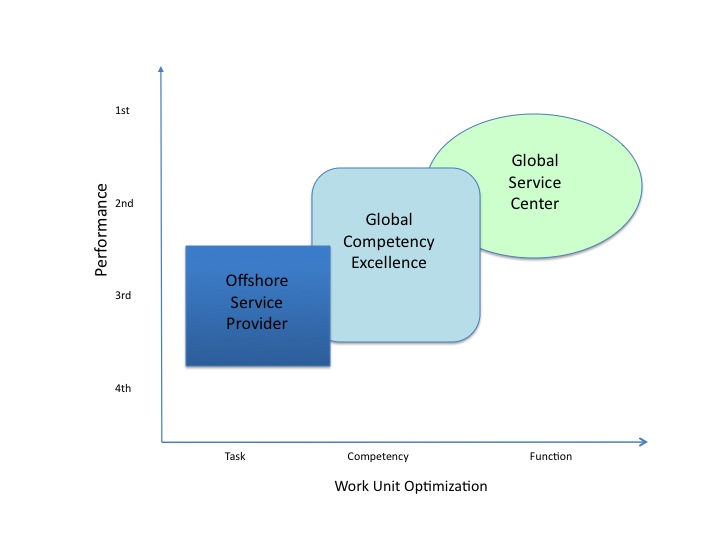 If you combine the functional optimization with a highly competitive site structure, you can typically organize key function in 2 or 3 locations where global functional leadership will reside. This then adds time of day and business continuity advantages. By having the same function at a minimum of two sites, then even if one site is down the other can operate. Or IT work can be started at one site and handed off at the end of the day at the next site that is just beginning their day (in fact most world class IT command centers operate this way). Thus no one ever works the night shift. And time to market can be greatly improved by leveraging such time advantages.
If you combine the functional optimization with a highly competitive site structure, you can typically organize key function in 2 or 3 locations where global functional leadership will reside. This then adds time of day and business continuity advantages. By having the same function at a minimum of two sites, then even if one site is down the other can operate. Or IT work can be started at one site and handed off at the end of the day at the next site that is just beginning their day (in fact most world class IT command centers operate this way). Thus no one ever works the night shift. And time to market can be greatly improved by leveraging such time advantages.
While it is understandably complex that you are optimizing across many variables (site location, contractor and skill mix, location cost, functional placement, competency placement, talent and skill availability), IT teams that can achieve a global team model and put in place global service centers reap substantial benefits in cost, quality, innovation, and time to market.
To properly weigh these factors I recommend a workforce plan approach where each each function or sub function maps out their staff and leaders across site, contractor/staff mix, and seniority mix. Lay out the target to optimize across all key variables (cost, capability, quality, business continuity and so on) and then construct a quarterly trajectory of the function composition from current state until it can achieve the target. Balance for critical mass, leadership, and likely talent sources. Now you have the draft plan of what moves and transactions must be made to meet your target. Every staff transaction (hires, rotations, training, layoffs, etc) going forward should be weighed against whether it meshes with the workforce plan trajectory or not. Substantial progress to an optimized global team can then be made by leveraging a rising tide of accumulated transactions executed in a strategic manner. These plans must be accompanied or even introduced by an overall vision of the global team and reinforcement of the goals and principles required to enable such an operating model. But once laid, you and your organization can expect to achieve far better capabilities and results than just dispersing tasks and activities around the world.
In today’s global competition, this global team approach is absolutely key for competitive advantage and essential for competitive parity if you are or aspire to be a top international company. It would be great to hear of your perspectives and any feedback on how you or your company been either successful (or unsuccessful) at achieving a global team.
I will add a subsequent reference page with Workforce Plan templates that can be leveraged by teams wishing to start this journey.
Best, Jim Ditmore


