There are over 5,000 books on applications development methods on Amazon. There are dozens of industry and government standards that map out the methodologies for application development. And for IT operations and IT production processes like problem and change management, IT Service Management and ITIL standards provide excellent guidance and structure. Yet for the infrastructure systems on which the applications rely on fully, there is scarcely a publication which outlines the approaches organizations should use to build and sustain a robust infrastructure. ITIL ventures slightly in this area but really just re-defines a waterfall application project cycle in infrastructure terms. During many years of building, re-building, and sustaining top quartile infrastructure I have developed a life cycle methodology for infrastructure or ‘Infrastructure Engineering Life Cycle’ (IELC).
The importance of infrastructure should not be overlooked in our digital age. Not only have customer expectations increased for services where they expect ‘always on’ web sites and transaction capabilities, but they also require quick response and seamless integration across offerings. Certainly the software is critical to provide the functionality, but none of these services can be reliably and securely provided without a well-built infrastructure underpinning all of the applications. A top quartile infrastructure delivers outstanding reliability (on the order of 99.9% or better availability), zippy performance, excellent unit costs, all with robust security and resiliency.
Often enterprises make the mistake of addressing infrastructure only when things break, and they only fix or invest enough to get things back running instead of re-building correctly a modern plant. It is unfortunate because not only will they likely experience further outages and service impacts but also their full infrastructure costs are likely to be higher for their dated, dysfunctional plant than for an updated, modern plant. Unlike most assets, I have found that a modern, well-designed IT infrastructure is cheaper to run than a poorly maintained plant that has various obsolete or poorly configured elements. Remember that every new generation of equipment can basically do twice as much s the previous so you have fewer components, less maintenance, less administration, less things that can go wrong. In addition, a modern plant also boosts time to market for application projects and reduces significantly the portion of time spent on fixing things by both infrastructure and application engineers.
So, given the critical nature of well-run technology infrastructure in the world of digitalization, how do enterprises and CIOs build and maintain a modern plant with outstanding fit and finish? It is not just about buying lots of new equipment, or counting on a single vendor or cloud provider to take care of all the integration or services. Nearly all major enterprise have a legacy of systems that result in complexity and complicate the ability to deliver reliable services or keep pace with new capabilities. These complexities can rarely be handled by a systems integrator or single service provider. Further, a complete re-build of the infrastructure often requires major capital investment and and can put the availability even further at risk. The best course is usually then is not to go ‘all-in’ where you launch a complete re-build or hand over the keys to a sole outsourcer, but instead to take a ‘spiral optimization’ approach which addresses fundamentals and burning issues first, and then uses the newly acquired capabilities to advance and address more complex or less pressing remaining issues.
A repeated, closed cycle approach (‘spiral optimization’) is our management approach. This management approach is coupled with an Infrastructure Engineering Lifecycle (IELC) methodology to build top quartile infrastructure. For the first cycle of the infrastructure rebuild, it is important to address the biggest issues. Front and center, the entire infrastructure team must focus on quality. Poorly designed or built infrastructure becomes a blackhole of engineering time as rework demands grow with each failure or application built upon a teetering platform. And while it must also be understood that a everything cannot be fixed at once, those things that are undertaken, must be done with quality. This includes documenting the systems and getting them correctly into the asset management database. And it includes coming up with a standard design or service offering if none exists. Having 5000 servers must be viewed as a large expense requiring great care and feeding — and the only thing worse is having 5000 custom servers because your IT team did not take the time to define the standard, keep it up to date, and maintain and patch it consistently. 5000 custom servers are a massive expense that likely cannot be effectively and efficiently maintained or secured by any team. There is no cheaper time than the present moment to begin standardizing and fixing the mess by requiring that the next server built or significantly updated be done such that it becomes the new standard. Don’t start this effort though until you have the engineering capacity to do it. A standard design done by lousy engineers is not worth the investment. So, as an IT leader, while you are insisting on quality, ensure you have adequate talent to engineer your new standards. If you do not have it on board, leverage top practitioners in the industry to help your team create the new designs.
In addition to quality and starting to do things right, there are several fundamental practices that must be implemented. Your infrastructure engineering work should be guided by the infrastructure engineering lifecycle – which is a methodology and set of practices that ensure high quality platforms that are effective, efficient, and sustainable.
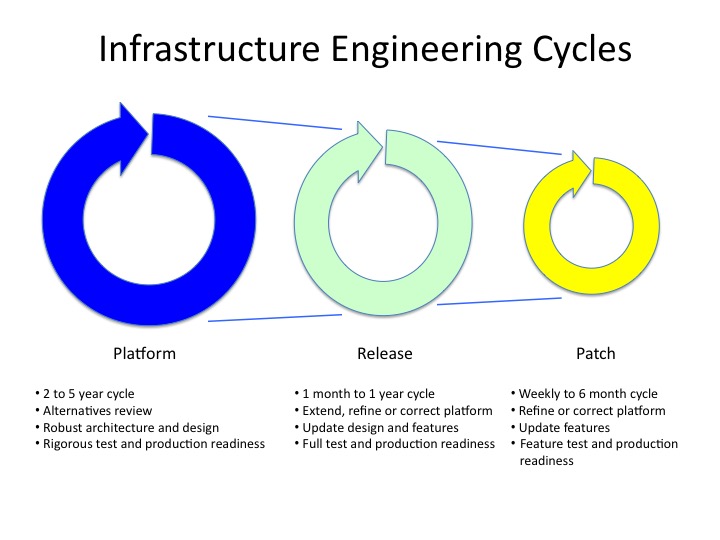
The IELC covers all phases of infrastructure platforms – from an emerging platform to a standard to declining and obsolete platforms. Importantly, the IELC is comprised of three cycles of activity that recognize that infrastructure requires constant grooming and patching where inputs come typically from external parties, and, all the while, technology advances regularly occur such that over 3 to 10 years nearly every hardware platform becomes obsolete and should and must be replaced. The three cycles of activity are:
- Platform – This is the foundational lifecycle activity where hardware and utility software is defined, designed and integrated into a platform to perform a particular service. Generally, for medium and large companies, this is a 3 to 5 year lifecycle. A few examples could be a server platform, storage platform or an email platform.
- Release – Once a platform is initial designed and implemented, then organizations should expect to refresh the platform on a regular basis to incorporate major underlying product or technology enhancements, address significant design flaws or gaps, and improve operational performance and reliability. Release should be planned for 3 to 12 month intervals over the life of the platform (which is usually 3 to 5 years).
- Patch – A patch should also be employed where on a regular and routine basis, minor upgrades (both fixes and enhancements) are applied. The patch cycle should synchronize with both the underlying patch cycle of the OEM (Original Equipment Manufacturer) for the product and with the security and production requirements of the organization. Usually, patch cycles are used to incorporate security fixes and significant production defect fixes issued by the OEM. Typical patch cycles can be weekly to every 6 months.
Below is a diagram that represents the three infrastructure engineering life cycles and the general parameters of the cycles.
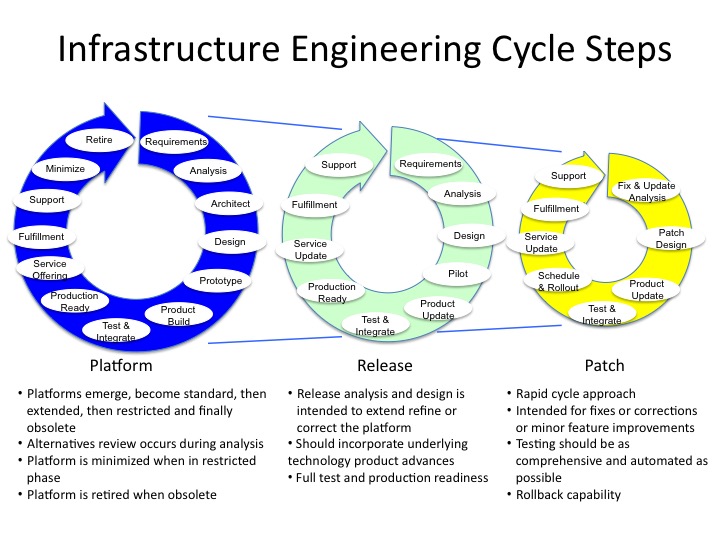
In subsequent posts, I will further detail key steps and practices within the cycles as well as provide templates that I have found to be effective for infrastructure teams. As a preview, here is the diagram of the cycles with their activities and attributes.
What key practices or techniques have you used for your infrastructure teams to enable them to achieve success? I look forward to you thoughts and comments.
Best, Jim Ditmore


