The typical IT shop spends 60% or more of its budget on external vendors – buying hardware, software, and services. Globally, the $2 trillion dollar IT marketplace (2013 estimate by Forrester) is quite inefficient where prices and discounts vary widely between purchasers and often not for reasons of volume or relationship. As a result, many IT organizations fail to effectively optimize their spend, often overpaying by 10%, 20%, or even much more.
Considering that IT budgets continue to be very tight, overspending your external vendor budget by 20% (or a total budget overrun of 12%) means that you must reduce the remaining 40% budget spend (which is primarily for staff) by almost 1/3 ! What better way to get more productivity and results from your IT team than to spend only what is needed for external vendors and plow these savings back into IT staff and investments or to the corporate bottom line?
IT expenditures are easily one of the most inefficient areas of corporate spending due to opaque product prices and uneven vendor discounts. The inefficiency occurs across the entire spectrum of technology purchases – not just highly complex software purchases or service procurements. I learned from my experience in several large IT shops that there is rarely a clear rationale for the pricing achieved by different firms other than they received what they competitively arranged and negotiated. To overcome this inefficient marketplace, the key prerequisite is to set up strong competitive playing fields for your purchases. With competitive tension, your negotiations will be much stronger, and your vendors will work to provide the best value. In several instances, when comparing prices and discounts between firms where I have worked that subsequently merged, it became clear that many IT vendors had no consistent pricing structures, and in too many cases, the firm that had greater volume had a worse discount rate than the smaller volume firm. The primary difference? The firm that robustly, competitively arranged and negotiated always had the better discount. The firms that based their purchases on relationships or that had embedded technologies limiting their choices typically ended up with technology pricing that was well over optimum market rates.
As an IT leader, to recapture the 6 to 12% of your total budget due to vendor overspend, you need to address inadequate technology acquisition knowledge and processes in your firm — particularly with your senior managers and engineers who are participating or making the purchase decisions. To achieve best practice in this area, the basics of a strong technology acquisition approach are covered here, and I will post on the reference pages the relevant templates that IT leaders can use to seed their own best practice acquisition processes. The acquisition processes will only work if you are committed to creating and maintaining competitive playing fields and not making decisions based on relationships. As a leader, you will need to set the tone with a value culture and focus on your company’s return on value and objectives – not the vendors’.
Of course, the technology acquisition process outlined here is a subset of the procurement lifecycle applied to technology. The technology acquisition process provides additional details on how to apply the lifecycle to technology purchases, leveraging the teams, and accommodating the complexities of the technology world. As outlined in the lifecycle, technology acquisition should then be complemented by a vendor management approach that repairs or sustains vendor performance and quality levels – this I will cover in a later post.
Before we dive into the steps of the technology acquisition process, what are the fundamentals that must be in place for it to work well? First, a robust ‘value’ culture must be in place. A ‘value’ culture is where IT management (at all levels) is committed to optimizing its company’s spending in order to make sure that the company gets the most for its money. It should be part of the core values of the group (and even better — a derivative of corporate values). The IT management and senior engineers should understand that delivering strong value requires constructing competitive playing fields for their primary areas of spending. If IT leadership instead allows relationships to drive acquisitions, then this quickly robs the organization of negotiating leverage, and cost increases will quickly seep into acquisitions. IT vendors will rapidly adapt to how the IT team select purchases — if it is relationship oriented, they will have lots of marketing events, and they will try to monopolize the decision makers’ time. If they must be competitive and deliver outstanding results, they will instead focus on getting things done, and they will try to demonstrate value. For your company, one barometer on how you are conduct your purchases is the type of treatment you receive from your vendors. Commit to break out of the mold of most IT shops by changing the cycle of relationship purchases and locked-in technologies with a ‘value’ culture and competitive playing fields.
Second, your procurement team should have thoughtful category strategies for each key area of IT spending (e.g. storage, networking equipment, telecommunications services). Generally, your best acquisition strategy for a category should be to establish 2 or 3 strong competitors in a supply sector such as storage hardware. Because you will have leveled most of the technical hurdles that prevent substitution, then your next significant acquisition could easily go to any of vendors . In such a situation, you can drive all vendors to compete strongly to lower their pricing to win. Of course, such a strong negotiating position is not always possible due to your legacy systems, new investments, or limited actual competitors. For these situations, the procurement team should seek to understand what the best pricing is on the market, what are the critical factors the vendor seeks (e.g., market share, long term commitment, marketing publicity, end of quarter revenue?) and then the team should use these to trade for more value for their company (e.g., price reductions, better service, long term lower cost, etc). This work should be done upfront and well before a transaction initiates so that the conditions favoring the customer in negotiations are in place.
Third, your technology decision makers and your procurement team should be on the same page with a technology acquisition process (TAP). Your technology leads who are making purchase decisions should be work arm in arm with the procurement team in each step of the TAP. Below is a diagram outlining the steps of the technology acquisition process (TAP). A team can do very well simply by executing each of the steps as outlined. Even better results are achieved by understanding the nuances of negotiations, maintaining competitive tension, and driving value.
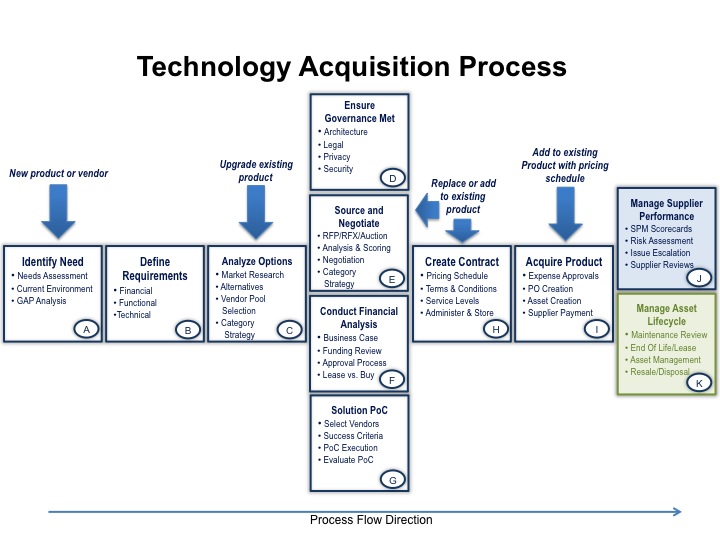
Here are further details on each TAP step:
A. Identify Need – Your source for new purchasing can come from the business or from IT. Generally, you would start at this step only if it is a new product or significant upgrade or if you are looking to introduce a new vendor (or vendors) to a demand area. The need should be well documented in business terms and you should avoid specifying the need in terms of a product — otherwise, you have just directed the purchase to a specific product and vendor and you will very likely overpay.
B. Define Requirements – Specify your needs and ensure they mesh within the overall technology roadmap that the architects have defined. Look to bundle or gather up needs so that you can attain greater volumes in one acquisition to possibly gain better better pricing. Avoid specifying requirements in terms of products to prevent ‘directing’ the purchase to a particular vendor. Try to gather requirements in a rapid process (some ideas here) and avoid stretching this task out. If necessary, subsequent steps (including an RFI) can be used to refine requirements.
C. Analyze Options – Utilize industry research and high level alternatives analysis to down-select to the appropriate vendor/product pool. Ensure you maintain a strong competitive field. At the same time, do not waste time or resources for options that are unlikely.
D, E, F, G. Execute these four steps in concurrence. First, ensure the options will all meet critical governance requirements (risk, legal, security, architectural) and then drive the procurement selection process as appropriate based on the category strategy. As you narrow or extend options, conduct appropriate financial analysis. If you do wish to leverage proofs of concept or other trials, ensure you have pricing well-established before the trial. Otherwise, you will have far less leverage in vendor negotiations after it has been successful.
H. Create the contract – Leverage robust terms and conditions via well-thought out contract templates to minimize the work and ensure higher quality contracts. At the same time, don’t forgo the business objectives of price and quality and capability and trade these away for some unlikely liability term. The contract should be robust and fair with highly competitive pricing.
I. Acquire the Product – This is the final step of the procurement transaction and it should be as accurate and automated as possible. Ensure proper receivables and sign off as well as prompt payment. Often a further 1% discount can be achieved with prompt payment.
J & K. The steps move into lifecycle work to maintain good vendor performance and manage the assets. Vendor management will be covered in a subsequent post and it is an important activity that corrects or sustains vendor performance to high levels.
By following this process and ensuring your key decision makers set a competitive landscape and hold your vendors to high standards, you should be able to achieve better quality, better services, and significant cost savings. You can then plow these savings back into either strategic investment including more staff or reduce IT cost for your company. And at these levels, that can make a big difference.
What are some of your experiences with technology acquisition and suppliers? How have you tackled or optimized the IT marketplace to get the best deals?
I look forward to hearing your views. Best, Jim Ditmore